

Have some concurrency control without having to add custom code.
One of the first non-trivial issues anyone working with an asynchronous execution will face is how to handle concurrency.
In this article, I will discuss the recent advancement of AWS to help deal with this more simply. But before let’s look at the problem and previous solutions available.
Concurrency With Asynchronous Executions 🔗
Imagine you have a system responsible for sending customer emails. Since it can take some time, it has been decided it will be handled asynchronously, without the user waiting for that to happen.

If you are using a more traditional approach, you have a worker that is connected to a message broker. The broker then pushes messages to the worker as they become available, causing the execution.
In this scenario, you can see yourself having many concurrent executions and potentially overloading downstream systems and dependencies, such as your persistence.

In order to avoid this issue, and prevent negative outcomes, you need to manage the concurrency of starting the executions. In the traditional setup, the simplest way it can take the form of processing messages synchronously, only taking new ones after the previous batch has been processed.
Now let’s see what was available in the serverless space until now.
Previous capabilities 🔗
When we consider the AWS serverless, you will define an event source, such as SQS, and the lambda service will responsible for retrieving a batch of messages and invoking your lambda functions.

This means that, by default, if you have many messages in the queue you can end up with a large number of lambda executions at the same time. Depending on your context this may not be desirable:
- You may be consuming too many of the available lambda executions quota, potentially throttling other use cases that are more important
- The downstream services, internal or external, may not be able to accommodate this simultaneous load
Up until recently, the only tool at your disposal at AWS lambda was to set the reserved concurrency parameter for a specific lambda. This has the effect of establishing a ceiling where no more than N instances of that function can be invoked at a given time.
When you pair that with the SQS event source, this means the lambda service would pick the batch of messages from SQS, and when it tries to invoke the lambda function it would not succeed.
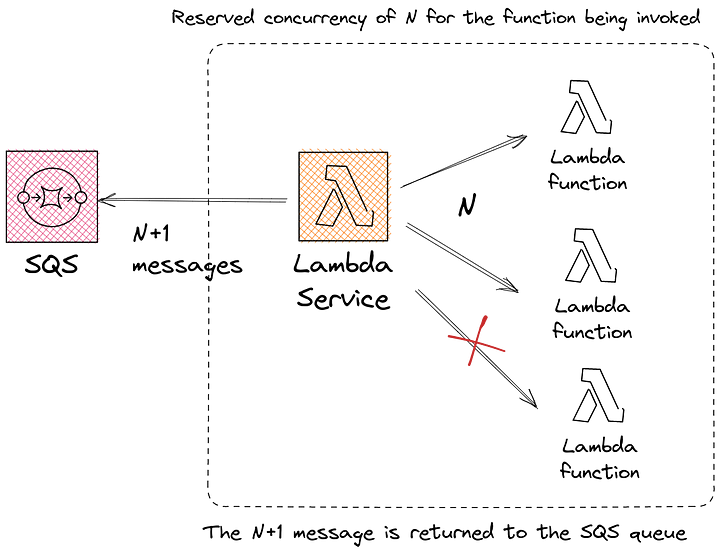
While that gets the job done there are at least two negative side effects:
- When you establish a reserved concurrency for one lambda function, you effectively remove this from the capacity available for all other lambdas in the same account.
This means that even if you have zero messages in the queue, all the other lambda functions will not be able to use the reserved concurrency invocations for themselves.
- If you fail to invoke the function too many times, you risk losing the messages or having them directed to a DLQ.
Since the lambda service retrieved the message and could not deliver it to the lambda function, the message is not removed from the queue. This means that in the next pooling cycle, the service will pick up the message again, increasing the number of delivery attempts. If it reaches the maxReceivingCount it will send the message to a DLQ.
Neither of the side effects is a deal breaker. Still, they require some extra effort, especially the DLQ one, as you would have to come up with a mechanism for separating poison messages (that would never be processed successfully) and those that ended up being there due to too many retries.
Meet the Maximum Concurrency for SQS 🔗
To address the “many retries lead to DLQ” issue we saw, AWS introduced a new parameter called maximum Concurrency when you choose SQS as your event source.
In a nutshell, what it does is stop the lambda service from retrieving new batches of messages from SQS if the concurrent number of executions for a given function has reached its configured limit.

Once the number goes below the maximum, the lambda service will resume picking more messages automatically. No more retries and you keep the DLQ really with messages that could not be processed!
This is a simple change that brings huge value to anyone that uses the standard SQS+lambda combo and wants to have some concurrency control without having to add custom code.

